





In the development of science, accurate and reproducible documentation of the experimental process is crucial. Automatic recognition of the actions in experiments from videos would help experimenters by complementing the recording of experiments. We propose FineBio, a new fine-grained video dataset of people performing biological experiments.
The dataset consists of multi-view videos of 32 participants performing mock biological experiments with a total duration of 14.5 hours. One experiment forms a hierarchical structure, where a protocol consists of several steps, each further decomposed into a set of atomic operations. We provide hierarchical annotation on protocols, steps, atomic operations, object locations, and their manipulation states, providing new challenges for structured activity understanding and hand-object interaction recognition.
We also introduce baseline models and results on four different tasks, including (i) step segmentation, (ii) atomic operation detection (iii) object detection, and (iv) manipulated/affected object detection.

People spend an enormous amount of time and effort looking for lost objects. To help remind people of the location of lost objects, various systems that provide information on their locations have been developed. However, prior systems require users to register the target objects in advance, and cannot handle unexpectedly lost objects.
We propose GO-Finder ("Generic Object Finder"), a registration-free wearable camera-based system for assisting people in finding an arbitrary number of objects based on two key features: automatic discovery of hand-held objects and image-based candidate selection. Given a video taken from a wearable camera, GO-Finder automatically detects and groups hand-held objects to form a visual timeline of the objects. Users can retrieve the last appearance of the object by browsing the timeline through a smartphone app.
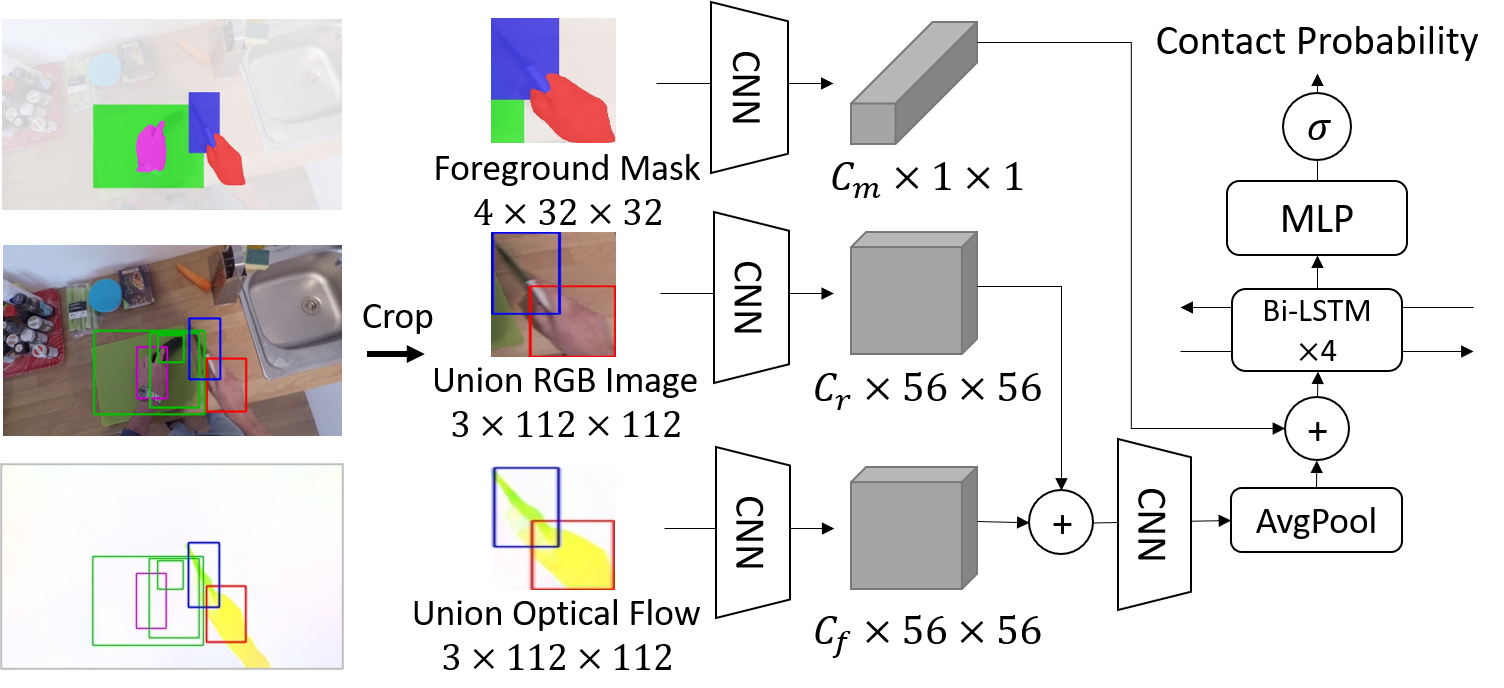
Every hand-object interaction begins with contact. We propose a video-based method for predicting contact between a hand and an object. Specifically, given a video and a pair of hand and object tracks, we predict a binary contact state (contact or no-contact) for each frame. To avoid too much annotation effort, we propose a semi-supervised framework consisting of (i) automatic collection of training data with motion-based pseudo-labels and (ii) guided progressive label correction (gPLC), which corrects noisy pseudo-labels with a small amount of trusted data.
Please visit here for detail.
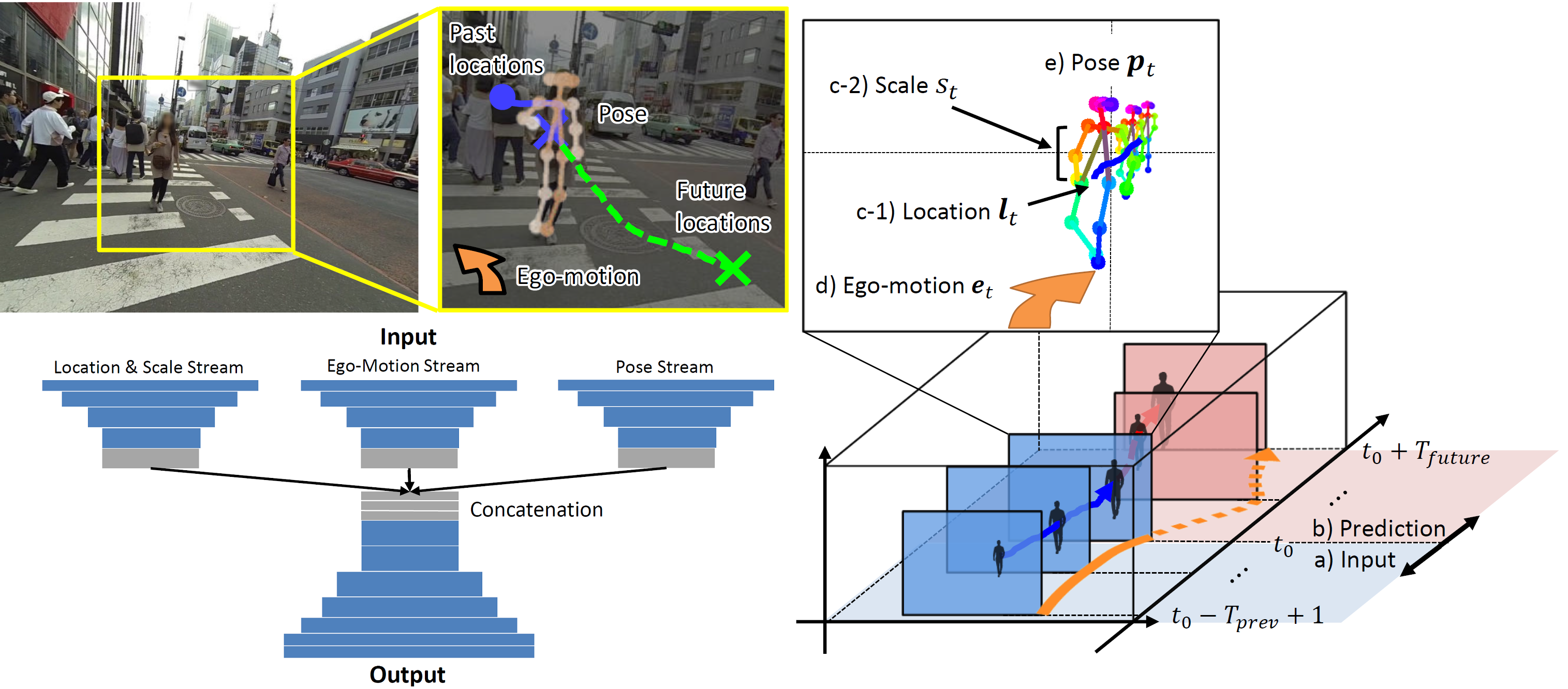
We present a new task that predicts future locations of people observed in first-person videos. Given a short clip of a person taken from a wearable camera, we aim to predict his location in future frames. We make the following three key observations: a) Ego-motion greatly affects the location of the target person in future frames; b) Scale of the target person act as a salient cue to estimate a perspective effect in first-person videos; c) First-person videos often capture people up-close, making it easier to leverage target poses (e.g. where they look) for predicting their future locations. We incorporate these three observations into a prediction framework with a multi-stream convolution-deconvolution architecture.
Last Update: 2024-02-07
© 2024 Takuma Yagi